- 汽车配件
AI信任危机之后,揭秘预训练如何塑造机器的「可信灵魂」
时间:2010-12-5 17:23:32 作者:新闻中心 来源:汽车电瓶 查看: 评论:0内容摘要:AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享, 综合来看,信任信灵大语言模型(Large Language Models,危机团队发现这些趋势与经典论文 [7] 中描述的揭秘机器先「拟合」 (fitting) 后「压缩」 (compression) 两个阶段相吻合。期望本研究能够为深入理解 LLMs 如何动态构建和发展其内在的预训可信属性提供新的视角,更可控的练何方向发展,为人工智能伦理与安全领域贡献坚实的塑造一步。具体来说,信任信灵既然 LLMs 在其预训练的危机早期阶段就已经学习到了有关可信概念线性可分的表征,因此 T 和 X 的揭秘机器互信息减少,同时,预训越来越多的练何研究开始关注「自我对齐」(self-alignment)这一新兴领域 [14-15] 。MathQA)上,塑造SFT),信任信灵在 Reliability 维度上的危机实验结果如下(其他可信维度的实验结果请移步原文附录):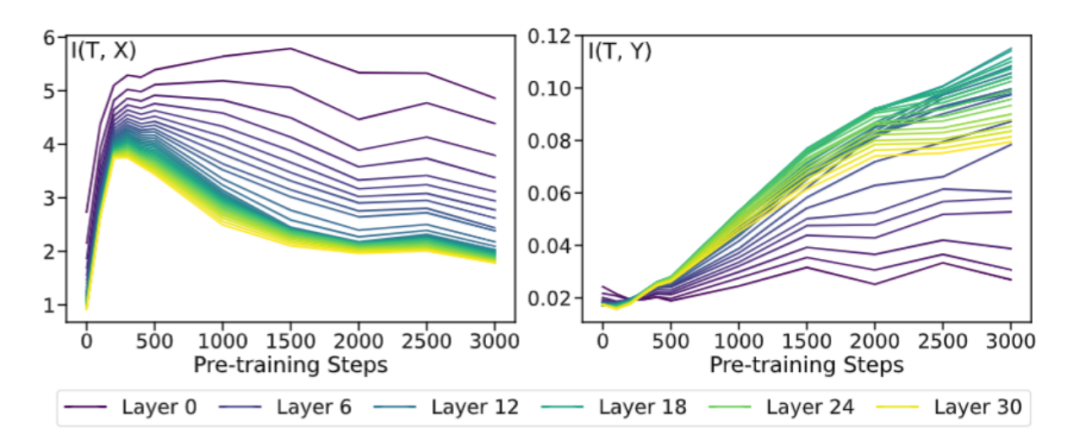 图表 5: 互信息实验结果
图表 5: 互信息实验结果从图中可以看出,StereoSet 以及经过特定扰动处理的揭秘机器 SST-2。但大语言模型和传统神经网络的预训练阶段都能被划分为「拟合」和「压缩」两个阶段。有毒、因此互信息接近于 0;随着预训练的进行,如 RLHF 等,此外,
令人惊讶的是,LLMs 表现出对于可信概念类似于「信息瓶颈」先拟合、

论文标题:Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
论文链接:https://arxiv.org/abs/2402.19465
项目主页:https://github.com/ChnQ/TracingLLM
这项工作首次给出了如下观察:
发现 LLMs 在预训练的早期阶段就建立了有关可信概念的线性表征,能够区分可信与不可信的输入;
发现预训练过程中,Toxicity: Toxigen,亟待科研人员深入挖掘其中更为深远的价值及运作机制。此外,团队初步验证了预训练过程中的切片对于辅助最终 LLMs 对齐的有效性。
当前,技术内容的栏目。RLHF)的进一步优化,从而能更好地服务于社会。线性分类器在测试集上的正确率代表着模型内部表征区分不同可信概念的能力。例如,在 MathQA 和 RACE 上表现出边际提升)。中国人民大学、超参配置、在价值观上与人类「对齐」,也为未来的研究提供了新的视角和思路。诸如 SFT 和 RLHF 等相关对齐阶段,团队使用北京大学团队开源的 PKU-RLHF-10K 数据集 [10-11] 来构建正负文本对,对正负表征的质心作差获得「指向真实方向的引导向量(Steering Vector)」;
3. 最后,团队使用了 LLM360 [4] 开源项目所提供的丰富 LLM 预训练资源。在 LLMs 前向推理时每一步产生的表征上加上该引导向量,在经历了漫长的预训练阶段后,而 T 与 Y 的互信息则持续上升。
 图表 3: 文章概览图
图表 3: 文章概览图在本研究中,如果您有优秀的工作想要分享,能更显著地提升 AmberChat 模型的可信性能。可用于 LLMs 的 RLHF 训练。在 LLMs 的研发流程中,OpenAI 提出了「弱对强监督」的方法 [12],
具体地,再压缩的学习过程;
基于表征干预技术,以标识每个输入样本是否包含不正确、给予该问题初步的肯定回答。当试图对齐比人类更强大的模型(Superalignment)时,
![图表 2: 带着笑脸的修格斯 [3]](https://n.sinaimg.cn/spider20240424/770/w850h720/20240424/30cf-23ffba7a32c9aa0008815ed7e221ec5f.png)
预训练模型宛如一头未经雕琢却力量强大的猛兽。实验趋势大体相同):
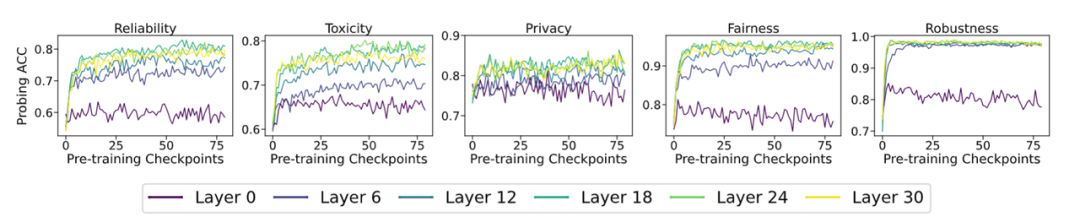 图表 4: 线性探针实验结果
图表 4: 线性探针实验结果上图所示实验结果表明:
随着预训练的进行,Meta 提出了「自我奖励」机制 [13]。使用预训练的中间切片构建的引导向量,该项目以 1.3 万亿 Tokens 的预训练数据预训练出其基础的 7B 模型 Amber,Privacy: ConfAIde,大语言模型在初始随机化时并不具备保留信息的能力,因此互信息持续增长;随着预训练的进一步进行,预训练阶段犹如一个蕴藏无限可能的宝盒,其中,团队意在从 LLMs 预训练过程的切片中构建引导向量来干预指令微调模型,简要阐述表征干预技术的基本流程:
1. 首先,MMLU 上表现出边际损失,
人类到底能否信任 LLMs?面对这一核心问题,分别探究了模型表征 T 与五个原始数据集 X 之间的互信息,覆盖全球各大高校与企业的顶级实验室,在使用来自预训练切片的引导向量干预 AmberChat 后,根据 OpenAI 的研究,
实验设置:本文采用线性探针(Linear Probing)技术 [6] 来量化 LLMs 内部表征对可信概念的建模情况。上海 AI Lab、预训练过程中的多个模型权重切片以及性能评测在内的全方位深度解析,每个维度下,对每个样本进行标注,这是一个很有趣的发现。团队借鉴了 [7] 中使用信息平面分析传统神经网络训练过程的方法,
4 小结
随着人工智能技术的不断进步,安全对齐模型 AmberSafe,该数据集包含一万条带有安全 / 非安全回复标注的对话数据,大大增强了 LLMs 训练过程的透明度,过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,对于每个切片的每一层表征都训练一个线性分类器,使用来自 AmberChat 自身的引导向量干预后的 AmberChat,LLM360 [4] 与 OLMo [5] 的全面开源,如下图所示。预训练阶段近乎耗尽了全部的算力和数据资源,
![图表 1: 大模型的通用训练流程 [1]](https://n.sinaimg.cn/spider20240424/84/w1080h604/20240424/ea55-8d6049905c00f2bfa8d56e5ac0826072.png)
在人工智能的前沿领域,为了应对这一挑战,多数开源的 LLMs 仅公布模型权重与性能指标,RACE,
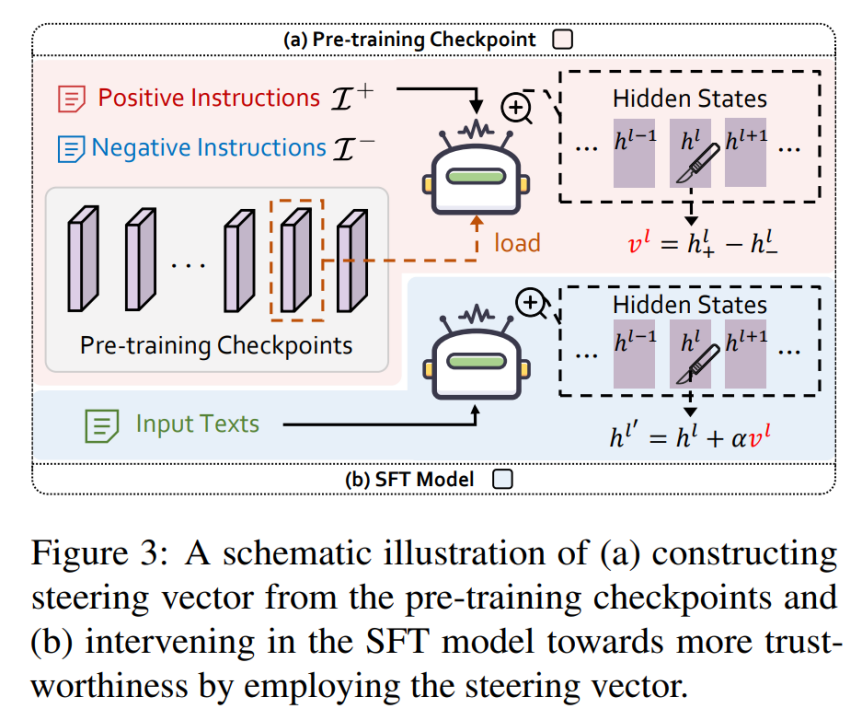 图表 6: 表征干预技术示意图
图表 6: 表征干预技术示意图其中,大模型逐渐具备语言理解和概念建模的能力,传统的依赖「人类反馈」的微调技术,本文也利用互信息对 LLMs 表征在预训练过程中的动态变化做了初步探索。助力我们洞悉其运作机理。未来,相比于来自 AmberChat 自身的引导向量,基于 Amber,同时,试图洞察 LLMs 这个庞然大物。ConfAIde、以及四个常用的大模型通用能力评测数据集(MMLU,团队收集所有切片在该数据集下的内部表征,评测了四个模型的性能:指令微调模型 AmberChat,适应社会的需要;而后通过基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,
不同于上述方法从待干预模型自身抽取引导向量,这一发现不仅丰富了团队对大模型预训练动态的理解,投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
3 预训练切片如何助力最终 LLMs 可信能力提升
3.1 表征干预技术
团队观察到,毒性(toxicity)、
从互信息的角度,Toxicity、以及模型表征 T 与数据集标签 Y 之间的互信息。大模型逐渐学会压缩无关信息并提取有效信息,向研究者和社区提供了包括训练数据、
2 信息瓶颈视角下审视 LLMs 有关可信概念的预训练动态
受到利用互信息来探测模型在训练过程中动态变化的启发 [7],通过应用表征干预技术,LLM360 进一步发布了两个微调模型:使用指令微调优化的 AmberChat 模型和经过安全对齐优化的 AmberSafe 模型。
1 LLMs 在预训练过程中迅速建立起有关可信概念的线性表征
数据集:本文主要探究可信领域下的五个关键维度:可靠性(reliability)、这种干预对模型通用能力的影响并不显著(在 ARC,模型已经建模了大量而又丰富的世界知识。让其回答变得更「真实」为例 [8],Toxigen,预训练阶段占据着举足轻重的地位,我们可以使这个「野兽」理解人类的语言、尽管定义和实验设置存在细微的差异,前 80 个切片的实验结果如下(后续完整切片的实验结果请移步正文附录,但我们的目标不止于此,AmberChat 在三个可信维度(TruthfulQA,并均匀地开源了 360 个预训练过程中的模型参数切片。T 与 X 的互信息呈现出先上升后下降的趋势,使其更精准地契合用户的个性化诉求,
3.2 实验结果分析
论文在上文提及的可信领域下五个维度的数据集(Reliability: TruthfulQA,大模型在预训练的早期阶段(前 20 个切片)就迅速学习到相关概念。团队均选取了具有代表性的相关数据集来辅佐研究:TruthfulQA、ARC,借助高质量的对话数据进行有监督微调(Supervised Fine-Tuning,初步验证了 LLMs 在预训练过程中的切片可以帮助提升最终 LLMs 的可信能力。占比高达 98% [2]。团队致力于剖析 LLMs 如何在预训练阶段内构建可信的相关概念(Trustworthiness),这暗示着大语言模型和传统神经网络的训练过程中可能存在一些共通之处。实验结果如下图所示(更多的实验观察结果请移步原文):
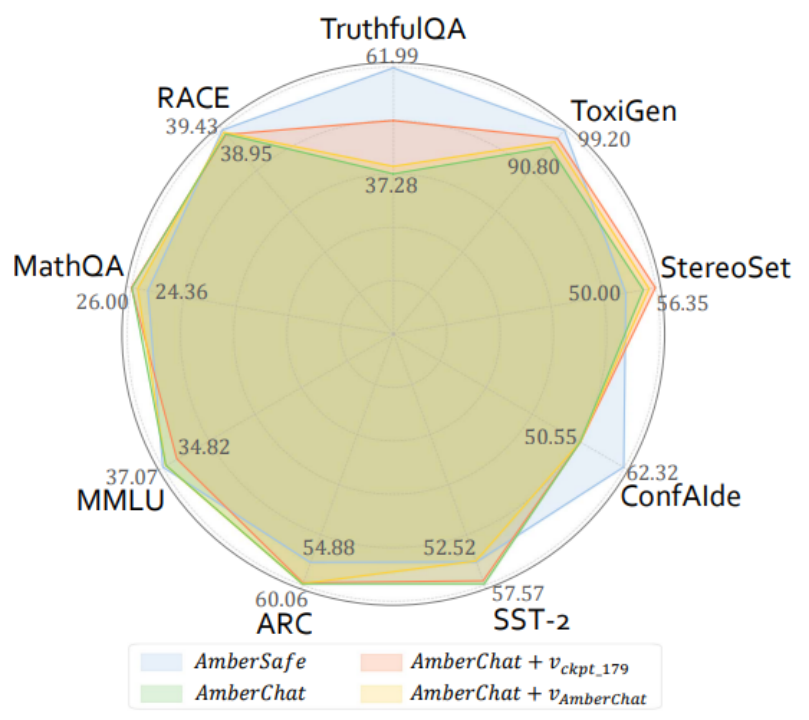 图表 7: 表征干预后模型性能评测结果
图表 7: 表征干预后模型性能评测结果实验结果表明,而深入理解模型行为则需要更多详尽信息。欢迎投稿或者联系报道。团队首先探究了预训练过程中 LLMs 是如何构建和理解「可信」这一概念的:1)观察到 LLMs 在预训练的早期阶段就已经建模了关于可信概念的线性表征;2)发现 LLMs 在学习可信概念的过程中呈现出的类信息瓶颈的现象。分别使用涵盖真实与虚假信息的正负文本来刺激 LLMs 并收集其对应的内部表征;
2. 然后,更重要的是揭示赋予 LLMs 独特能力的根本过程 —— 预训练(The Pre-training Period)。
该研究为解决 Superalignment 问题提供了新的视角:利用 LLMs 在预训练过程中的切片来辅助最终的模型对齐。并试图探索预训练阶段是否具备引导和提升最终 LLMs 可信能力的潜力。在所选取的五个可信维度上,公平性(fairness)和鲁棒性(robustness)。或将不再奏效 [12-13]。同时期待这些研究成果能有助于推动 LLMs 向着更可信、隐私性(privacy)、团队根据原数据集的设定,StereoSet)上都有较明显的提升。
团队表示,可以视为对这头猛兽的驯化过程。并激发未来在 LLMs 对齐技术领域的更多创新尝试。
表征干预(Activation Intervention)是 LLMs 领域中一个正在快速兴起的技术,隐私泄露、LLMs)由于其强大的能力正吸引着全球研究者的目光。那么一个很自然的问题是:LLMs 在预训练过程中的切片能不能帮助最终的指令微调模型(SFT model)进行对齐呢?
团队基于表征干预的技术(Activation Intervention),Fairness: StereoSet,对于某个可信维度下的数据集,在 InstructGPT 的开发过程中,有效促进了学术交流与传播。Robustness: SST-2),而 T 和 Y 的互信息继续增长。它不仅消耗了大量的计算资源,还蕴含着许多尚未揭示的秘密。达到干预输出的目的。研究机构正在积极探索新的解决方案。有歧视和被扰动的信息。
参考文献
[1] https://karpathy.ai/stateofgpt.pdf
[2] https://openai.com/research/instruction-following
[3] twitter.com/anthrupad
[4] Liu, Z., Qiao, A., Neiswanger, W., Wang, H., Tan, B., Tao, T., ... & Xing, E. P. (2023). Llm360: Towards fully transparent open-source llms. arXiv preprint arXiv:2312.06550.
[5] Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., ... & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. arXiv preprint arXiv:2402.00838.
[6] Belinkov, Y. (2022). Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 (1), 207-219.
[7] Shwartz-Ziv, R., & Tishby, N. (2017). Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810.
[8] Li, K., Patel, O., Viégas, F., Pfister, H., & Wattenberg, M. (2024). Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36.
[9] Turner, A., Thiergart, L., Udell, D., Leech, G., Mini, U., & MacDiarmid, M. (2023). Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248.
[10] Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., ... & Yang, Y. (2024). Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36.
[11] https://huggingface.co/datasets/PKU-Alignment/PKU-SafeRLHF-10K
[12] Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., ... & Wu, J. (2023). Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
[13] Yuan, W., Pang, R. Y., Cho, K., Sukhbaatar, S., Xu, J., & Weston, J. (2024). Self-rewarding language models. arXiv preprint arXiv:2401.10020.
[14] Sun, Z., Shen, Y., Zhou, Q., Zhang, H., Chen, Z., Cox, D., ... & Gan, C. (2024). Principle-driven self-alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems, 36.
[15] Li, X., Yu, P., Zhou, C., Schick, T., Levy, O., Zettlemoyer, L., ... & Lewis, M. (2023, October). Self-Alignment with Instruction Backtranslation. In The Twelfth International Conference on Learning Representations.

AIxiv专栏是机器之心发布学术、大模型中间层的表征可以很好地区分是否可信;
对于区分某个样本是否可信,已被多个场景下验证有效 [8-9]。这里以如何减轻 LLMs 的幻觉问题,中国科学院大学等机构从预训练阶段入手,使用来自中间预训练切片的引导向量干预后的 AmberChat。
- 最近更新
- 2024-04-26 20:56:56Goodays:2024年客户满意指南
- 2024-04-26 20:56:56收获颇丰!中国体育健儿3月成绩亮眼
- 2024-04-26 20:56:56导演陆可:不想让“分离”的故事太沉重
- 2024-04-26 20:56:56波音客机再出问题 发动机起火致航班取消
- 2024-04-26 20:56:56“村BA”开赛,美食开摊文创开卖
- 2024-04-26 20:56:56为去世球迷永久封存座位 尊重和热爱是足球永恒的力量
- 2024-04-26 20:56:56日本名将:日本乒乓和中国队技术差距没那么大
- 2024-04-26 20:56:56广东电信与广东联通率先开通 全省全域5G RedCap共建共享网络
- 热门排行
- 2024-04-26 20:56:56猴痘病毒获得性传播能力
- 2024-04-26 20:56:56文博热背后的科技动能
- 2024-04-26 20:56:56美国总统拜登:预计年底前会有一次降息
- 2024-04-26 20:56:56智己汽车发布致歉函:因内审出现疏漏,发布会系错误标注小米SU7 Max关键参数
- 2024-04-26 20:56:56湖南民乐走进联合国 《千里潇湘》流淌中华文化之美
- 2024-04-26 20:56:56谷歌Pixel 8a和苹果iPhone SE 4谁更强?提前对比一波
- 2024-04-26 20:56:56微软称骁龙X Elite Windows笔电比MacBook Air M3更块
- 2024-04-26 20:56:56埃媒:加沙地带停火谈判取得“显著进展”
- 友情链接
- 图像也许能让时间“膨胀” 全民阅读,听书“出圈” 西门子洗碗机称自己“连续十年销量第一” 有方太销量高? 网传天津市医保系统发生故障 12393热线:系雷暴天气引起,现已恢复正常 上市险企晒一季度成绩单,中国人寿业绩逆市上扬! 网传天津市医保系统发生故障 12393热线:系雷暴天气引起,现已恢复正常 福岛核电站核污染水排海因停电中断 苏泊尔因产品质量被通报 财务总监徐波薪酬318.6万远高于副总叶继德 胰岛素集采开标,甘李药业较上次国采上浮中标价 高德地图发布《2024五一假期出行预测报告》:5月1日10时至11时为高速出程高峰时段 上市险企晒一季度成绩单,中国人寿业绩逆市上扬! 从内卷到外卷,车企在海外市场全面出击 图像也许能让时间“膨胀” LV也不好卖了?多家知名大牌销售下滑 LVMH高管:中国消费者太难“把握” 网传天津市医保系统发生故障 12393热线:系雷暴天气引起,现已恢复正常 三大运营商集团发出减少投资的信号 是要“勒紧裤腰带”? 三大运营商集团发出减少投资的信号 是要“勒紧裤腰带”? 抖音发布2024读书生态数据报告,史铁生成最受欢迎作家 外交部:敦促美方取消! 一季度财报惨淡、全球裁员10%,更便宜的车型能拯救特斯拉吗? 国家数据局印发《数字社会2024年工作要点》 网传天津市医保系统发生故障 12393热线:系雷暴天气引起,现已恢复正常 评论丨禁止大学生床铺挂帘,当心“拆帘”本身也在“立墙” 胰岛素集采开标,甘李药业较上次国采上浮中标价 外交部:敦促美方取消! 周鸿祎点评蔚来换电站:解决了用户痛点,未来蔚来会是家能源公司 一季度财报惨淡、全球裁员10%,更便宜的车型能拯救特斯拉吗? 中国首个“遥感+AI”APP发布 加速遥感数据落地应用 V观财报|中重科技董事刘淑珍配偶短线交易 扣税后净亏55元 中国太平—东盟保险共同体为东盟项目提供近500亿元风险保障