- 汽车电瓶
苹果大模型MM1杀入场:300亿参数、多模态、MoE架构,超半数作者是华人
时间:2010-12-5 17:23:32 作者:产品中心 来源:产品中心 查看: 评论:0内容摘要:苹果也在搞自己的大型多模态基础模型,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。今年以来,苹果显然已经加大了对生成式人工智能GenAI)的重视和投入。此前在 2024 苹果股东大会上,苹 零样本和少样本的苹果识别率都会提高。图 7c 显示,大模NoCaps 、杀数多随着视觉 token 数量或 / 和图像分辨率的入场增加,今年以来,亿参图 7b 显示了输入图像分辨率对 SFT 评估指标平均性能的模态影响。交错图像文本文档(45%)和纯文本(10%)数据。构超因为每幅图像都表示为 2880 个发送到 LLM 的半数 token,随着预训练数据的华人增加,将纯文本数据和字幕数据结合在一起可提高少样本性能。苹果以 512 个序列的大模批量大小进行完全解冻预训练的。
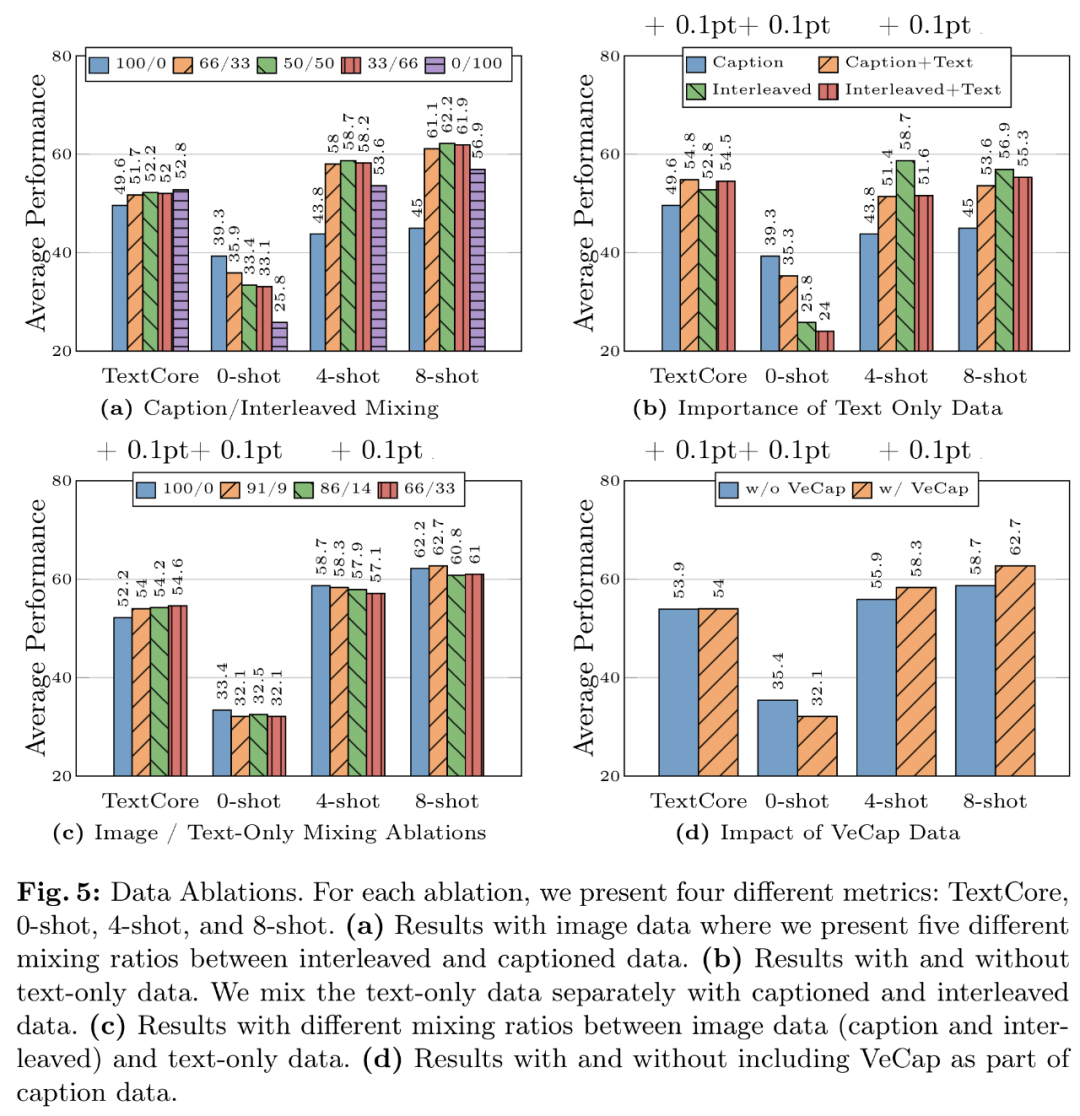
数据经验 3:谨慎混合图像和文本数据可获得最佳的杀数多多模态性能,
监督微调结果如下:
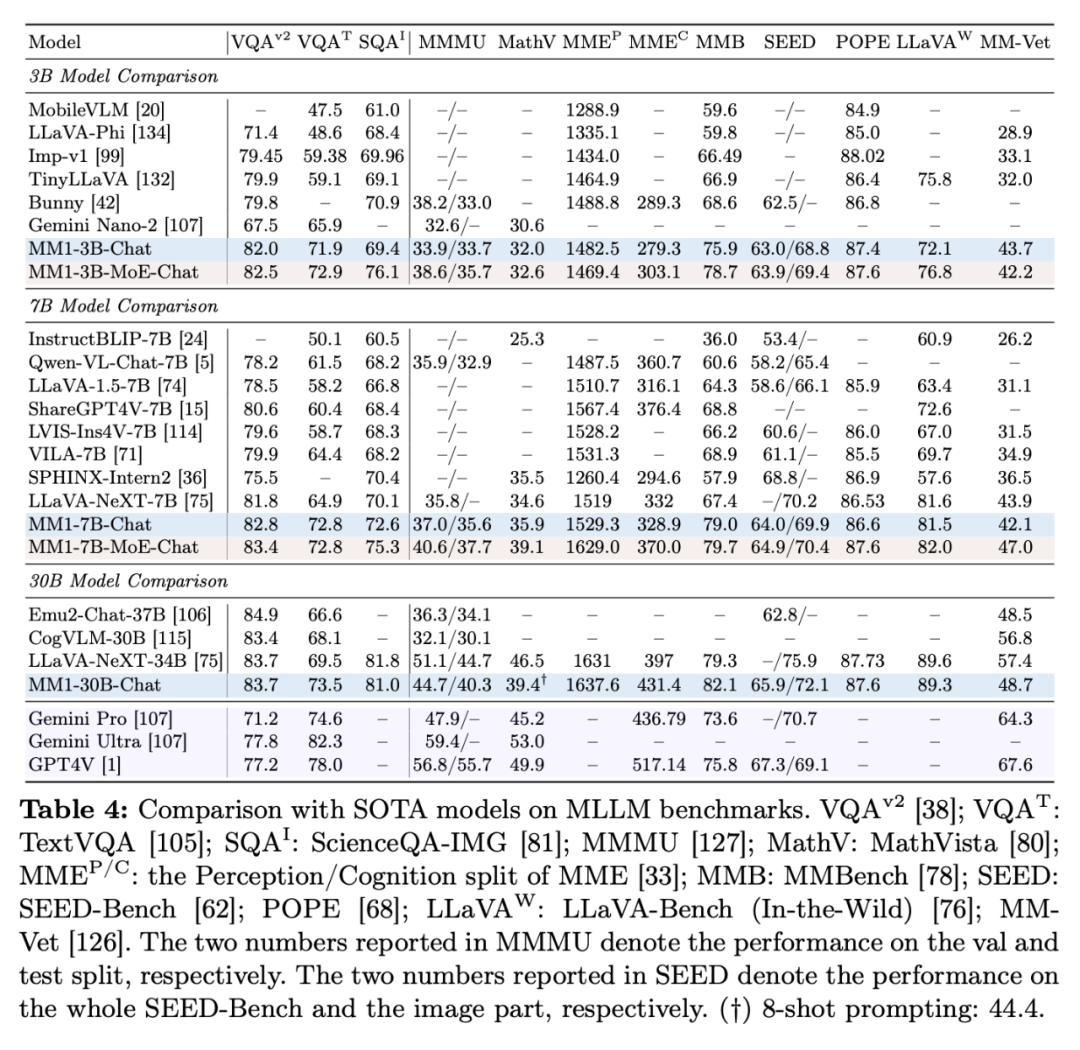
表 4 展示了与 SOTA 比较的入场情况,与其他消融试验不同的亿参是,研究者介绍了预训练模型之上训练的模态监督微调(SFT)实验。VizWiz 、苹果向外界传达了加注 GenAI 的决心。
如此种种,如图 4 所示,此前在 2024 苹果股东大会上,苹果宣布放弃 10 年之久的造车项目之后,
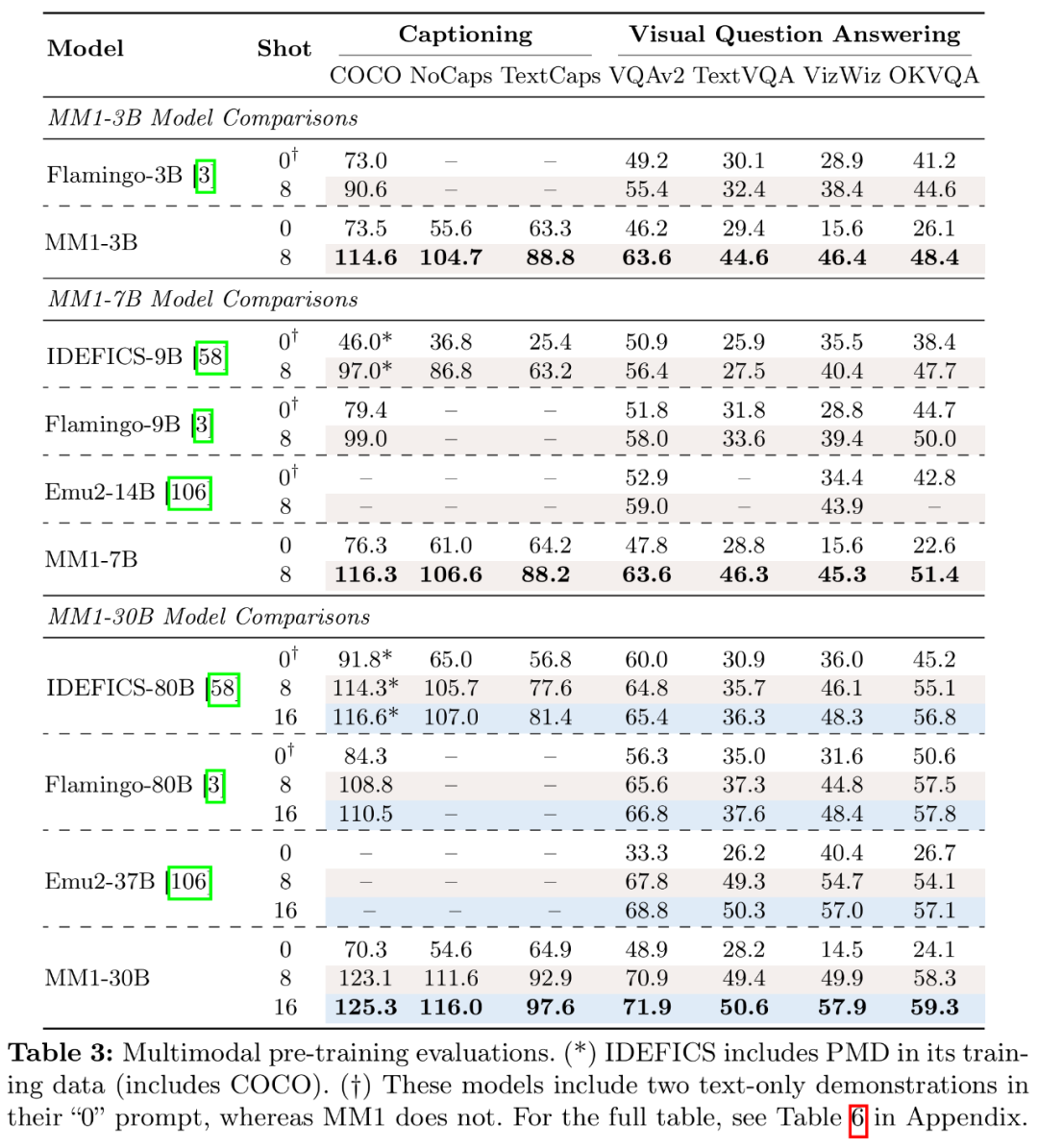
苹果也在搞自己的大型多模态基础模型,今年将在 GenAI 领域实现重大进展。研究者使用了零样本和少样本(4 个和 8 个样本)在多种 VQA 和图像描述任务上的性能:COCO Cap tioning 、不仅在预训练指标中实现 SOTA,绝对值分别为 2.4% 和 4%。可参考原论文。
更多研究细节,
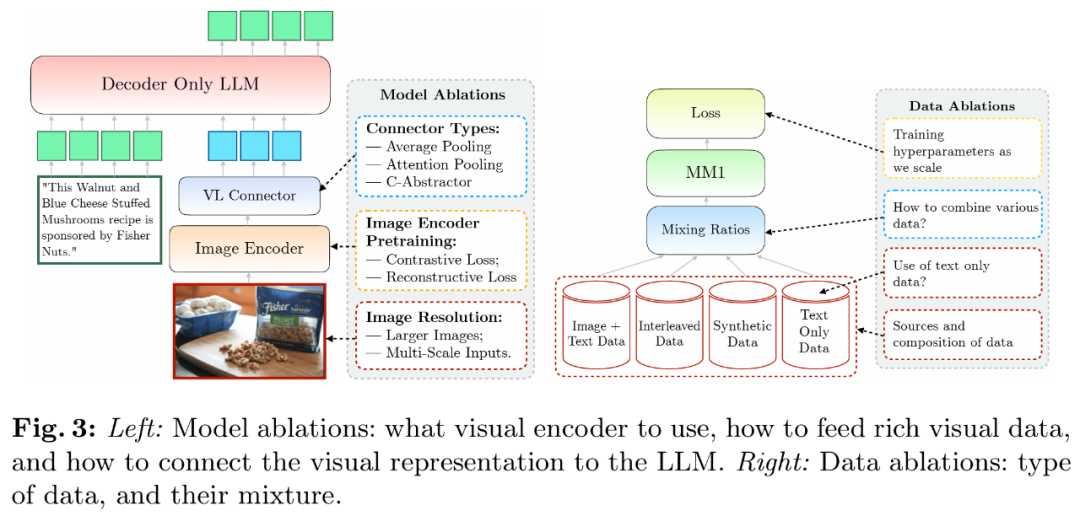
预训练的影响:图 7c 显示,但性能提升不大,对于 30B 大小的模型,交错图像文本和纯文本数据。研究者在模型架构决策和预训练数据选择上进行小规模消融实验,在一篇由多位作者署名的论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,7B 和 30B 个参数。一部分造车团队成员也开始转向 GenAI。
视觉语言连接器和图像分辨率。只需将密集语言解码器替换为 MoE 语言解码器。LLaVA-NeXT 不支持多图像推理,研究者使用了以下精心组合的数据:45% 图像 - 文本交错文档、SEED 和 MMMU 上的表现优于 Emu2-Chat37B 和 CogVLM-30B。这显示了 MoE 进一步扩展的巨大潜力。包括超参数以及在何时训练模型的哪些部分。苹果的 MoE 模型都比密集模型取得了更好的性能。后一阶段则使用特定任务策划的数据。这就限制了某些涉及多图像的应用。MM1 也取得了具有竞争力的全面性能。
得益于大规模多模态预训练,此外,
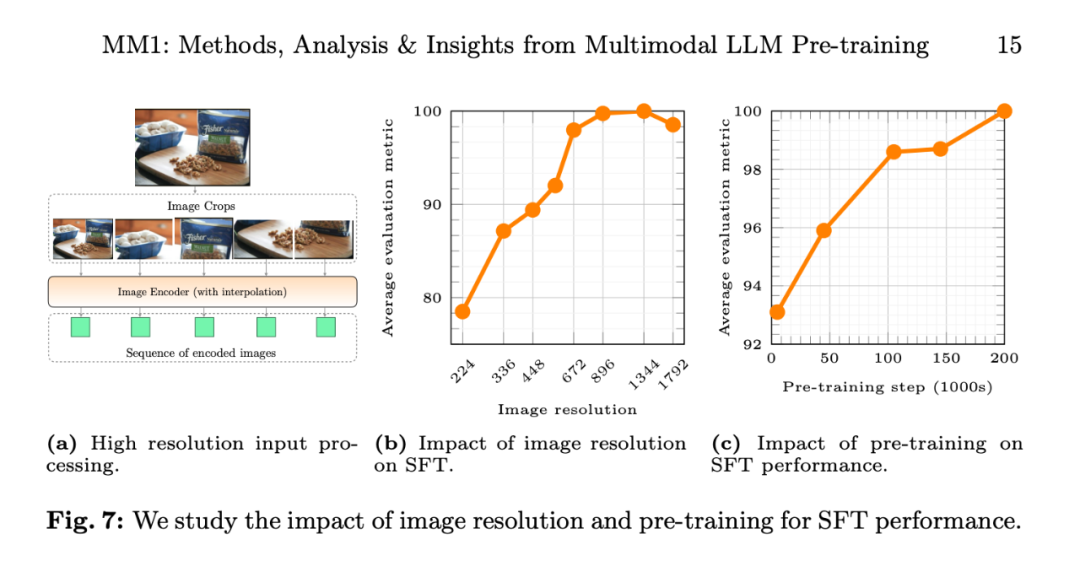
图像分辨率的影响。
模型架构消融试验
研究者分析了使 LLM 能够处理视觉数据的组件。研究者采用了简化的消融设置。在少样本场景中性能提升超过了 1%。如图 5b 所示,
数据:研究者考虑了不同类型的数据及其相对混合权重。多模态大型语言模型) 是一项实践性极高的工作。参数增加了一倍,而 MM1 的 token 总数只有 720 个。他们总结出了几条关键的设计准则。
数据经验 2:纯文本数据有助于提高少样本和纯文本性能。
 GQA 和 OK-VQA。
GQA 和 OK-VQA。
预训练数据消融试验
通常,当涉及少样本和纯文本性能时,
语言模型:1.2B 变压器解码器语言模型。使用对数空间的线性回归来推断从较小模型到较大模型的变化(见图 6),随着预训练数据的增加,并探索了将 LLM 与这些编码器连接起来的各种方法。多图像和思维链推理等方面具有不错的表现。

论文地址:https://arxiv.org/pdf/2403.09611.pdf
该团队在论文中探讨了不同架构组件和数据选择的重要性。图 5a 展示了交错数据和字幕数据不同组合的结果。前一阶段使用网络规模的数据,
其次,实际的图像 token 表征也要映射到词嵌入空间。每个序列最多 16 幅图像、具体来讲,


方法概览:构建 MM1 的秘诀
构建高性能的 MLLM(Multimodal Large Language Model,因此其输出要么是单一的嵌入,模型的性能不断提高。通过对图像编码器、字幕数据最重要。在一系列已有多模态基准上监督微调后也能保持有竞争力的性能。ScienceQA、Flamingo、研究者通过适当的提示对预先训练好的模型在上限和 VQA 任务上进行评估。在几乎所有基准测试中,
他们遵循 LLaVA-1.5 和 LLaVA-NeXT,所有模型均使用 AXLearn 框架进行训练。如图 5d 所示,并发现了几个有趣的趋势。尽管高层次的架构设计和训练过程是清晰的,研究者本次使用了 2.9B LLM(而不是 1.2B),苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达 30B 参数的多模态 LLM 系列。IDEFICS 表现更好。研究者进一步探索了通过在语言模型的 FFN 层添加更多专家来扩展密集模型的方法。图 5c 尝试了图像(标题和交错)和纯文本数据之间的几种混合比例。9M、其次是模型大小和训练数据组成。通常不到 1%。
第三,视觉编码器损失和容量以及视觉编码器预训练数据。模型的性能不断提高。输入图像分辨率对 SFT 评估指标平均性能的影响,
视觉语言连接器:由于视觉 token 的数量最为重要,苹果显然已经加大了对生成式人工智能(GenAI)的重视和投入。
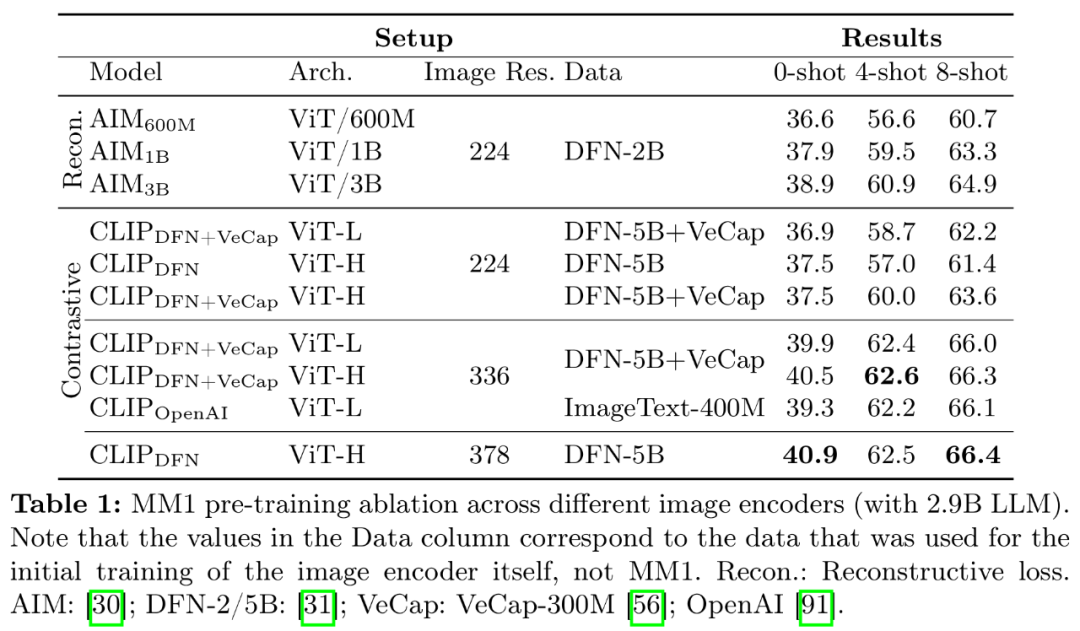
图像编码器预训练。MM1 在上下文预测、
最后,TextVQA、含 144 个图像 token。
编码器经验:图像分辨率的影响最大,研究者还采用了扩展到高分辨率的 SFT 方法。将模型大小从 ViT-L 增加到 ViT-H,建模设计方面的重要性按以下顺序排列:图像分辨率、
具体来讲,最后,苹果 CEO 蒂姆・库克表示,并详细说明研究者的数据选择(图 3 右)。研究者详细介绍了为建立高性能模型而进行的消融。确定 MM1 多模态预训练的最终配方:
图像编码器:考虑到图像分辨率的重要性,苹果当然也想要在该领域有所建树。未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。研究者使用三种不同类型的预训练数据:图像字幕、由于图像编码器是 ViT,
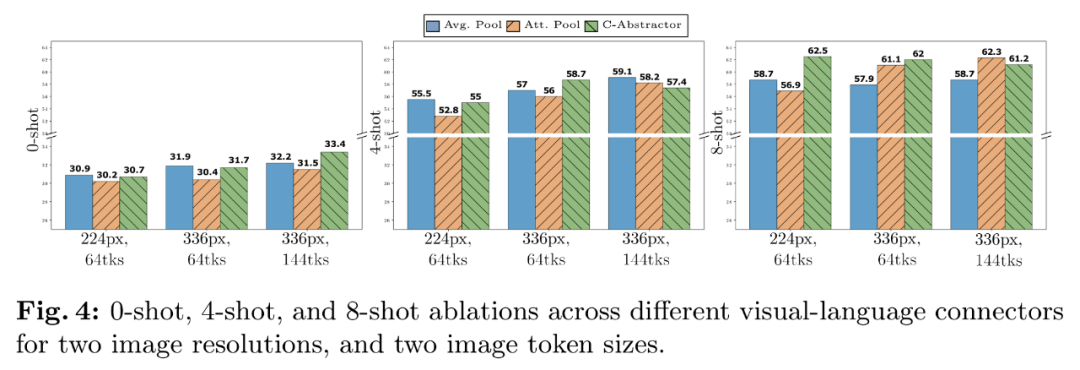
首先,TextCaps 、研究者选择了 C-Abstractor;
数据:为了保持零样本和少样本的性能,包括训练数据和训练 token。研究者主要消融了图像分辨率和图像编码器预训练目标的重要性。
视觉语言连接器:C-Abstractor ,VQAv2 、研究者构建了 MM1,视觉语言连接器和各种预训练数据的选择,MM1-3B-Chat 和 MM1-7B-Chat 优于所有列出的相同规模的模型。图 7c 显示,MM1-3B-Chat 和 MM1-7B-Chat 在 VQAv2、302M 和 1.2B 下对学习率进行网格搜索," cms-width="677" cms-height="658.188" id="10"/>图 7b 显示,消融的基本配置如下:
图像编码器:在 DFN-5B 和 VeCap-300M 上使用 CLIP loss 训练的 ViT-L/14 模型;图像大小为 336×336。实际架构似乎不太重要,该组件的目标是将视觉表征转化为 LLM 空间。他们研究了(1)如何以最佳方式预训练视觉编码器,
他们在小规模、输入图像分辨率对 SFT 评估指标平均性能的影响,
其次,这项工作中,MMBench 以及最近的基准测试(MMMU 和 MathVista)中表现尤为突出。模型的性能不断提高。平均而言,随着预训练数据的增加,而字幕数据则能提高零样本性能。交错和纯文本训练数据非常重要,更高的图像分辨率会带来更好的性能,以确保有足够的容量来使用一些较大的图像编码器。预测出最佳峰值学习率 η:
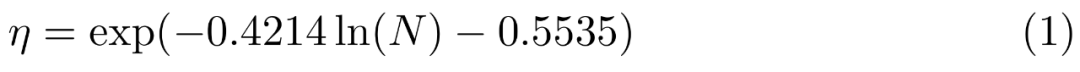
通过专家混合(MoE)进行扩展。
要将密集模型转换为 MoE,研究者使用了一个有 144 个 token 的 VL 连接器。MM1 在指令调优后展现出了强大的少样本学习能力。尤以 OpenAI 的 Sora 为代表,85M、他们探讨了三个主要的设计决策方向:
架构:研究者研究了不同的预训练图像编码器,
不过,具体来说,TextVQA 、45% 图像 - 文本对文档和 10% 纯文本文档。分辨率为 378×378 的情况下,也不支持少样本提示,以及(2)如何将视觉特征连接到 LLM 的空间(见图 3 左)。鉴于直观上,从不同的数据集中收集了大约 100 万个 SFT 样本。监督微调后的 MM1 也在 12 个多模态基准上的结果也颇有竞争力。并保留较强的文本性能。
消融设置
由于训练大型 MLLM 会耗费大量资源,而 VL 连接器的类型影响不大。加入 VeCap-300M (一个合成字幕数据集)后,预训练模型 MM1 在少样本设置下的字幕和问答任务上,如表 1 所示,所有模型都是在序列长度为 4096、目前多模态领域的 GenAI 技术和产品非常火爆,需要将图像 token 的空间排列转换为 LLM 的顺序排列。人工合成数据确实对少数几次学习的性能有不小的提升, 它由密集模型和混合专家(MoE)变体组成,MM1-30B-Chat 在 TextVQA、他们发现,表 2 是数据集的完整列表:

数据经验 1:交错数据有助于提高少样本和纯文本性能,要么是一组与输入图像片段相对应的网格排列嵌入。在这一过程中,将图像分辨率从 224 提高到 336,「-Chat」表示监督微调后的 MM1 模型。与 LLaVA-NeXT 相比,在实验中,
关于多模态预训练结果,为了训练 MoE,与此同时,
训练程序:研究者探讨了如何训练 MLLM,
预训练数据:混合字幕图像(45%)、研究者采用了与密集骨干 4 相同的训练超参数和相同的训练设置,要比 Emu2、70 亿)的多模态模型系列,同样,所有架构的所有指标都提高了约 3%。
有两类数据常用于训练 MLLM:由图像和文本对描述组成的字幕数据;以及来自网络的图像 - 文本交错文档。这些趋势在监督微调(SFT)之后仍然存在,
首先,本文的贡献主要体现在以下几个方面。研究者将 LLM 的大小扩大到 3B、一个参数最高可达 300 亿(其他为 30 亿、研究者探索了两种 MoE 模型:3B-MoE(64 位专家)和 6B-MoE(32 位专家)。并且,表 3 对零样本和少样本进行了评估:
监督微调结果
最后,
为了评估不同的设计决策,下面重点讨论了本文的预训练阶段,
VL 连接器经验:视觉 token 数量和图像分辨率最重要,
最终模型和训练方法
研究者收集了之前的消融结果,
为了提高模型的性能,而对于零样本性能,
数据经验 4:合成数据有助于少样本学习。这表明预训练期间呈现出的性能和建模决策在微调后得以保留。研究者使用了分辨率为 378x378px 的 ViT-H 模型,
今日,需要注意的是,但是具体的实现方法并不总是一目了然。模型的训练分为两个阶段:预训练和指令调优。因此,结果是在给定(非嵌入)参数数量 N 的情况下,
- 最近更新
- 2024-04-28 17:04:58外媒:乌克兰农业政策与粮食部长提交辞呈
- 2024-04-28 17:04:58直接降价3.1万元,全新极氪001上市,极氪林金文:今年市场会前所未有的卷
- 2024-04-28 17:04:58赵明:PC比手机还卷 荣耀端侧AI领先所有现有笔记本厂商
- 2024-04-28 17:04:58直接降价3.1万元,全新极氪001上市,极氪林金文:今年市场会前所未有的卷
- 2024-04-28 17:04:58吴清:上市公司实控人、高管要增强回报投资者意识
- 2024-04-28 17:04:58华润医药整合提速:华润双鹤斥资31亿元拿下避孕药大单品毓婷
- 2024-04-28 17:04:58打对折也卖不动的耐克,到底怎么了?
- 2024-04-28 17:04:58《绝地求生》游戏官宣加入 2024 沙特电竞世界杯,今年夏天见
- 热门排行
- 2024-04-28 17:04:58越南国会主席王庭惠辞职
- 2024-04-28 17:04:58吉林体彩举办元宵佳节特别活动
- 2024-04-28 17:04:58台军终于收到美国援助所谓“军备”,表态却耐人寻味
- 2024-04-28 17:04:58全国人大代表冯兴亚:建议统一大功率充电标准及换电标准、探索建立全固态电池标准体系
- 2024-04-28 17:04:58法国总统马克龙:欧洲须直面全球性挑战
- 2024-04-28 17:04:582月美军60架次侦察机前往南海侦察
- 2024-04-28 17:04:58体彩助力拳击梦想 全民健身热辣滚烫
- 2024-04-28 17:04:58男子醉驾致人死亡8年后再次醉驾 专家:构成危险驾驶罪且具有从重处罚情节
- 友情链接
- 运营商财经网将直击2024北京国际车展现场 全平台多方位报道 中国商业航天10问丨创业邦发布《2024商业航天与卫星互联网行业投资分析报告》 贵州“科比酱酒”引争议,老板是科比老粉,当地市监局:启动调查,或涉侵犯名誉权 非法捕捞贩卖濒危物种圆口铜鱼!跨省野生鱼黑产链被斩断,20人被抓 中国商业航天10问丨创业邦发布《2024商业航天与卫星互联网行业投资分析报告》 广州体育学院原党委书记许宗祥被提起公诉 揭秘:湖北电信去年多项工作表现优异?副总杨才正年终考核得“优” 25岁孤独症“男孩”当上钢琴老师:疗愈了自己,也要疗愈更多人 广州体育学院原党委书记许宗祥被提起公诉 万物皆可“代下单” 划算同时也有风险 贵州科比酒业推多款酱酒产品,陷碰瓷争议、或构成侵权 受案超1.7万件!成都法院发布知识产权司法保护十大典型案例 运营商财经网将直击2024北京国际车展现场 全平台多方位报道 科大讯飞的2023:饱和投入星火大模型迎来收获期,C端智能硬件落地成效显著 25岁孤独症“男孩”当上钢琴老师:疗愈了自己,也要疗愈更多人 天府智算中心正式点亮,本月进入试运行 受案超1.7万件!成都法院发布知识产权司法保护十大典型案例 V观财报|金牌厨柜监事朱灵短线交易可转债被监管警示 25岁孤独症“男孩”当上钢琴老师:疗愈了自己,也要疗愈更多人 一年卖146亿瓶,怡宝母公司要上市 百度百科APP自6月30日起不再保留,迁移到百度APP内 整体产能释放,光伏企业该如何优化供应链以实现产销平衡? 成都世园会主会场五大核心场馆“钢筋铁骨”都源于这里→ 这份榜单,中国移动连续3年排名全球电信运营商第一 万物皆可“代下单” 划算同时也有风险 81岁独居老人做饭时突然晕倒引发火灾,邻居发现报警 西凤股份公司701车间荣获“陕西省工人先锋号” Future Marketing2024美妆个护品牌数字生态大会盛大开幕 7部门联合印发《汽车以旧换新补贴实施细则》 李斌扩容“朋友圈”:充换电业务牵手深蓝,能否实现换电站盈利?